












Mark tells us how the Engineering Team resolved a mysterious problem...
Littered throughout our tech blogs, you’ll start to hear a common term; CI - Continuous Integration. The idea is pretty simple - for every branch or bit of code we change, we spin up a fully functional Glean environment on a special set of servers (our CI Kubernetes cluster).
To help explain - here’s a quick Excalidraw with our basic setup.
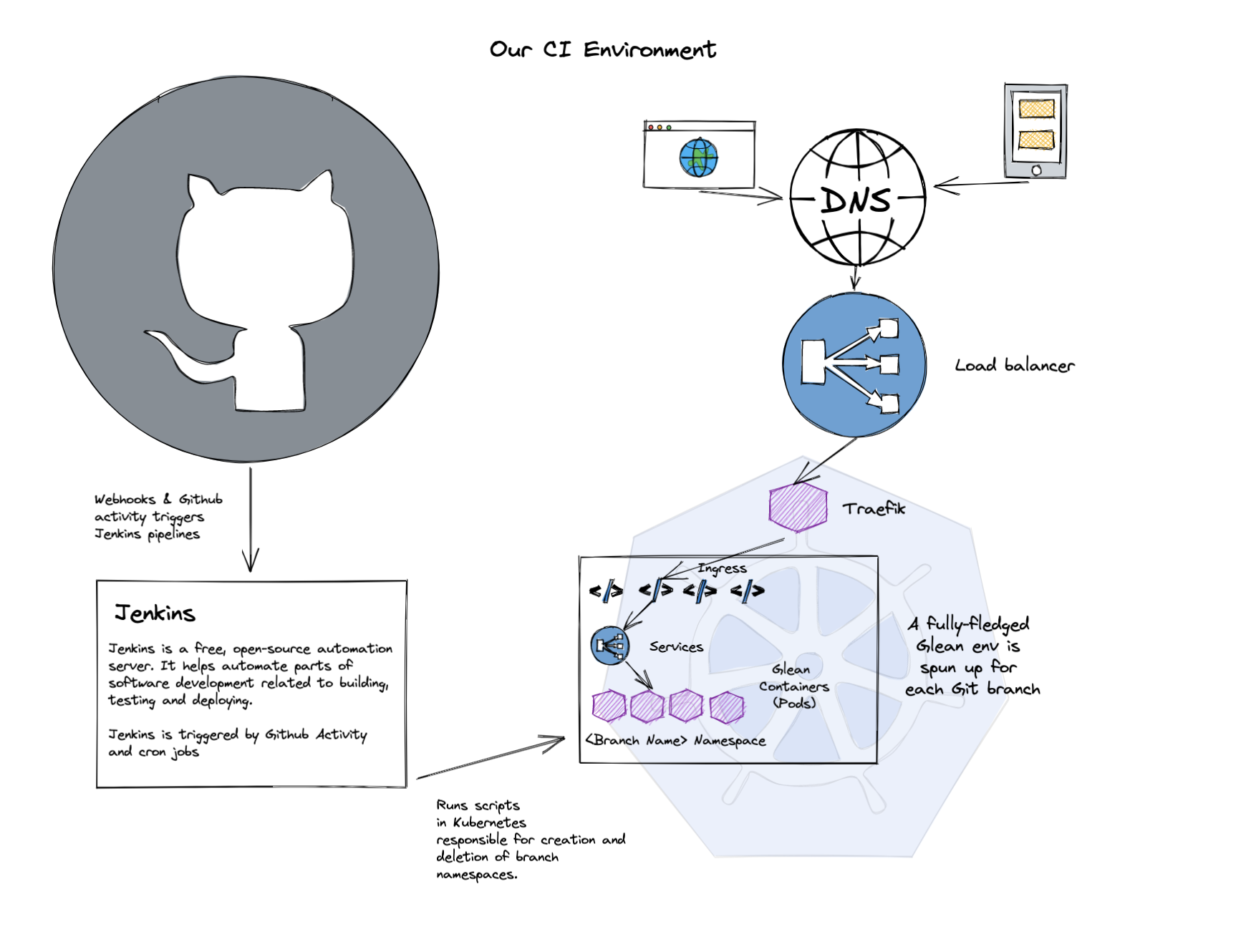
When the environment comes online, we run hundreds of tests against it, clicking on buttons that our users would click on and ensuring we get the expected results. It gives us the confidence that our code changes haven't broken any other functionality inadvertently, saving lots of tester time, and getting our code changes out into the wild so much faster.
How the day started
One Tuesday morning in April, we found out just how important CI is to our development process. We woke up, checked Slack and found the familiar “Kubernetes Upgrade” notification. This means overnight, when our developers aren’t coding away, Kubernetes automatically patched and upgraded to a new version. This time, it was a major bump to v1.19. A quick sanity check and everything appeared to function as expected. As per usual, things were working fine.
[discrepancy detected]
It wasn’t until much later that day that we started to see something strange happening.
12 hours after the upgrade had completed - Jenkins, our CI software, had started to log connection errors to the Kubernetes API. This was a brand new error, nothing we’d seen before: “error dialing backend: dial timeout” with a 500 response code.
We’ve seen almost identical errors in Jenkins before, but one word difference. We did the usual restarting Jenkins, restarting the Jenkins runner pods for each of the jobs running on our nodes. But alas, this wasn’t going anywhere. One by one, our pipelines ground to a halt. Everything was red, nothing was building and developers were unable to develop.
About Kubernetes
For those less familiar with Kubernetes, it distributes containers on various servers (known as nodes). Our CI cluster is fairly large - sitting around 45 servers on a busy day. This is so we can build lots and lots of code simultaneously and run ~50 versions of Glean. So there are lots of servers to troubleshoot and pinpoint where the issue is.
A typical Kubernetes cluster comes with an array of static pods that perform things like DNS lookup inside the cluster (i.e. how do I go from http://<service-name>.<namespace> to 10.0.2.4). SSH tunnels for executing commands inside of pods, Networking pods…. The list really goes on. And sadly, a Google search of the error message above didn’t give us any hints where to look. In fact, it was coming up almost empty.

All of the pods in the kube-system namespace were clear of errors. Our logging stack was coming up empty. We had nowhere to turn to at this point other than raising a case with our Cloud provider.
Meanwhile...
Our development team had well and truly ground to a halt. Whilst all of the tests I mentioned before can be done locally, it’s very slow, and while things were red - we agreed as a team nothing should be merged (i.e. no code changes should leave developers' branches).
Time passed, we checked repeatedly. We recreated node pools, upgraded Jenkins, bumped some plugins. But suddenly, we noticed that something interesting was in the release notes from our Cloud provider.
A new connectivity mechanism had been activated in our version bump called Konnectivity.
Traditionally, you connect to pods using SSH tunnels. However, Konnectivity uses a TCP level proxy to execute these commands. Something we’d never used before and not as widely used in the community just yet. The only issue… we don’t have any control over Konnectivity or SSH tunnels as they come as part of our Managed Kubernetes service. So we were at the mercy of our support ticket.
We provided our findings, escalated to a P1 incident and called it a day. Wednesday morning appeared. Things were still in a bad state. We started Plan B: recreate the whole thing.
Our action plan
With the ambiguity around Konnectivity and those hidden elements of Kubernetes managed by our cloud provider to play with, we had lots of educated guesses around what could be the issue. Logs were flying everywhere in our Slack conversations. But we all agreed on the best approach; we opted to roll forward rather than back.
Hoping that if we went bleeding-edge (i.e. the most recent version of Kubernetes 1.19 available to us), that whatever the issue was, it could have already been patched. Alternatively, if this issue was something that only impacted this one cluster of ours due to some strange environmental issue, a fresh start could help.
We manage almost every bit of our infrastructure using Terraform, or if we really can’t use Terraform, scripting like Bash & Python comes to the rescue. But things had really changed in the 18 months since we last created the cluster.
I joined the company and made lots of changes to make managing Kubernetes that little bit easier. Which meant lots of new elements were added! It had been a very long time since we burnt the lot and recreated it from scratch, not to mention the complexity of trying to work together on it over Slack & Google Hangouts.
We took the backups of the persistent volumes that we needed and started running the terrifying commands.
$ helm -n kube-system uninstall external-dns
$ helm -n kube-system uninstall cert-manager
$ helm -n traefik uninstall traefik
$ terraform state rm kubernetes_cluster.ci_cluster
We opted to keep our current cluster online to support the investigations into what was going wrong with our cloud provider. So we decided to remove the elements that could cause any conflict with our new cluster. External-DNS (updates Route53 with the IP address for our Ingress objects), Cert-Manager which issues the SSL certs and Traefik - our Ingress controller. Finally, we removed the cluster from Terraform state. We ran the command:
$ terraform plan
[...]
Plan: 3 to add, 25 to change, 7 to destroy.
The command returned with lots of elements needing recreating, newly creating or updating. A quick scan, and some handy awk piping to filter through the things we didn’t want to touch just yet. We were ready to bring the new cluster online.
And?
The new cluster came online. We were able to connect with Kubectl. It was empty, it was new and it was ready for more. We did use Terraform’s target argument to bring up just the cluster at first. This was so we could run some tests on the cluster to see if it was experiencing the same issues as our old cluster before we threw everything at it at once.
As a quick sanity check, we’d discovered that running this command was able to replicate the issue outside of Jenkins on our old cluster:
$ kubectl run -i --tty --rm --image=busybox some-name
Error attaching, falling back to logs: error dialing backend: dial timeout
Although the error wasn’t appearing on the new cluster, even after hundreds of executions of the command. The cluster was on an ever-so-slightly newer version of Kubernetes, which appeared to not experience the same bug. Hurray!
Now the cluster was online, we started to bring the basic elements back.
$ terraform apply --target=helm_release.filebeat \ --target=helm_release.external-dns \
--target=helm_release.cert-manager \
--target=helm_release.traefik \
--target=helm_release.kibana
Now we had all the basics that we needed for connectivity and logging. We were ready for the big ones:
$ terraform apply --target=helm_release.jenkinsFinally - the rest that we targeted around:
$ terraform applyAfter a minute or two allowing the DNS to propagate...
Jenkins was online!
Jobs were building!
Now, it was time to try running master (our main branch on Git)...
It passed! We’re online.
Happily ever after
Our CI environments were building again. Developers were back up to full speed. Merges into master restarted and new versions of Glean released. 24 hours were lost, although, other than the new cluster name our Terraform code hadn’t let us down, those 18 months of changes continued to work and Terraform remained the source of truth.
A few days passed, we assisted our cloud provider with logging, information and access to servers. The result - a memory leak in Konnectivity (see the fix PR here). Unfortunately, the version of Konnectivity rolled out in our dev-cluster wasn’t the patched version.
Once patched, the issue never reoccurred on our old cluster. However, it was now redundant and was destroyed. Thanks for your 18 months of service, dev-cluster!
Join us
We’re always on the lookout for fresh talent to join our Engineering Team. To see the latest opportunities, visit our Careers Page!
Share this blog






Time for a simpler, smarter note taking accommodation?



